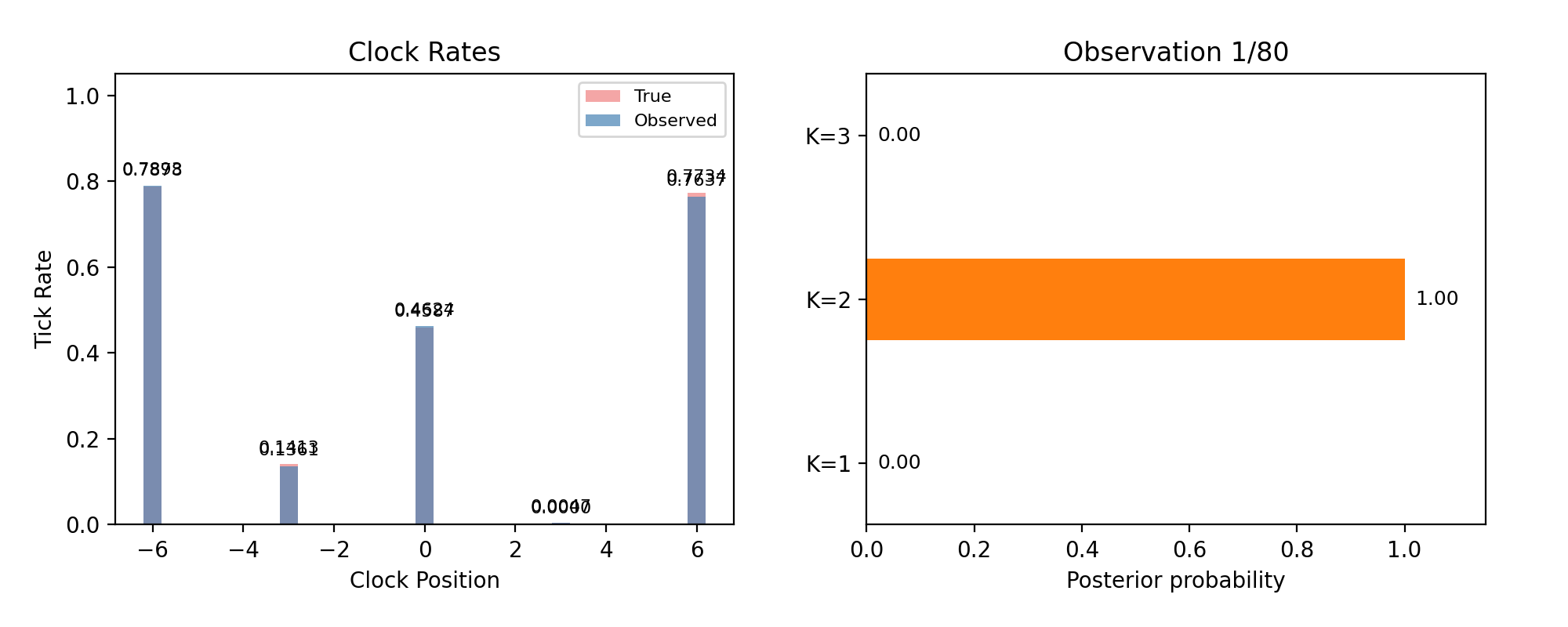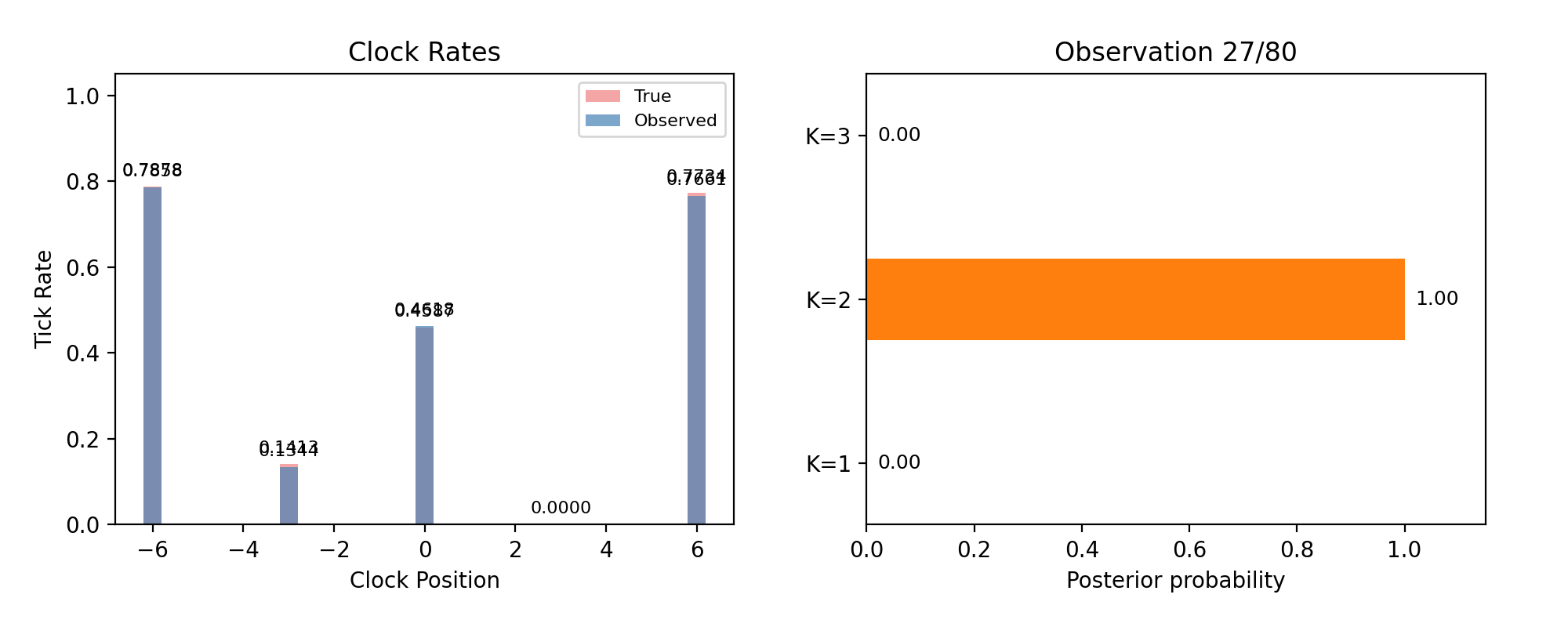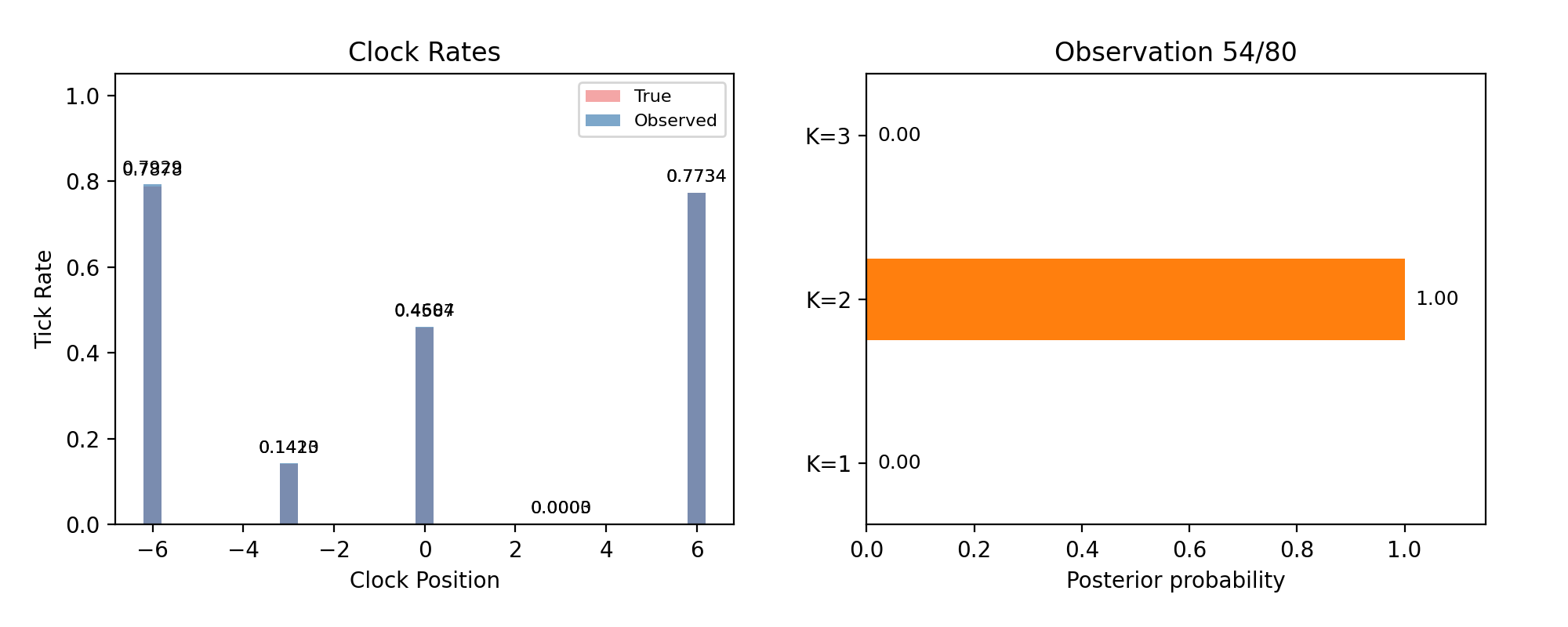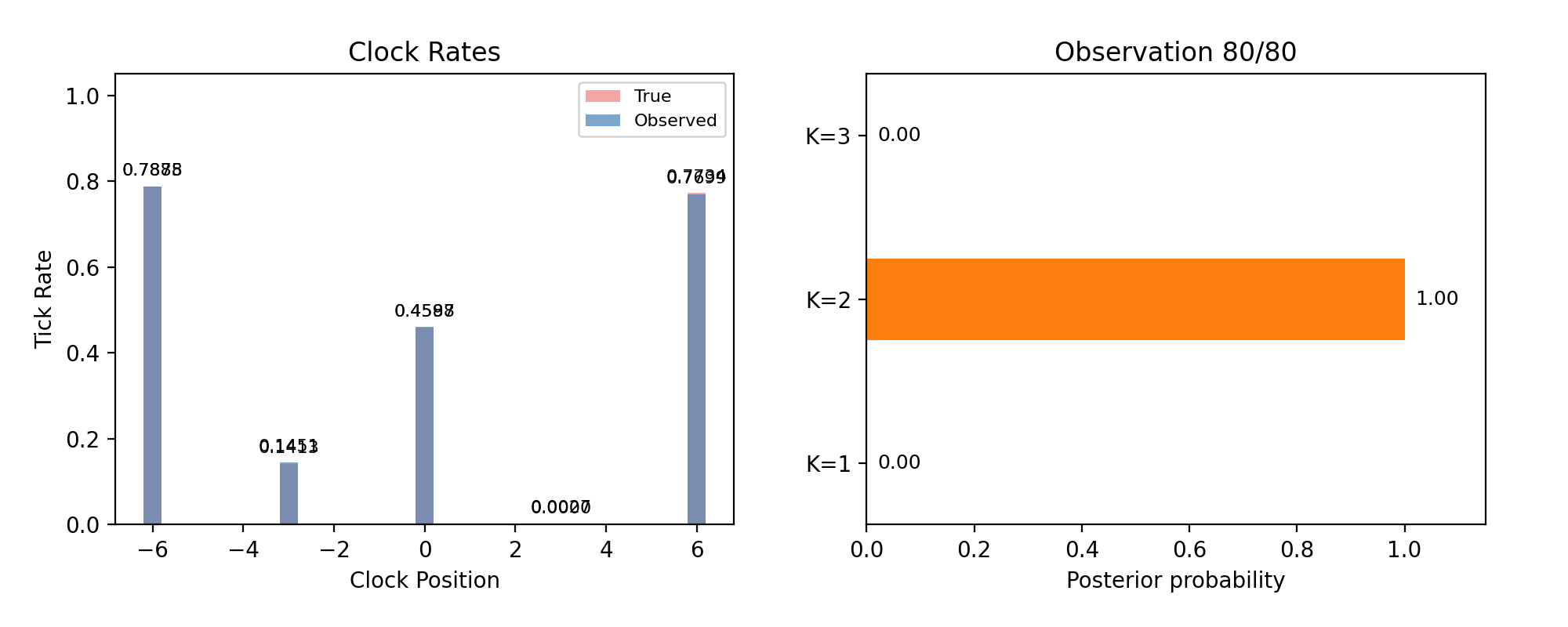
Every page so far fixed the number of masses in advance — detection with the answer key half-open. Real detection must infer the model, not just its parameters. The Bayesian answer is to run a separate particle filter for each candidate count \(K\) and compare evidence: the probability each model assigned to the data it actually saw, accumulated observation by observation. Models that need the data explained to them lose; models that predicted it win.
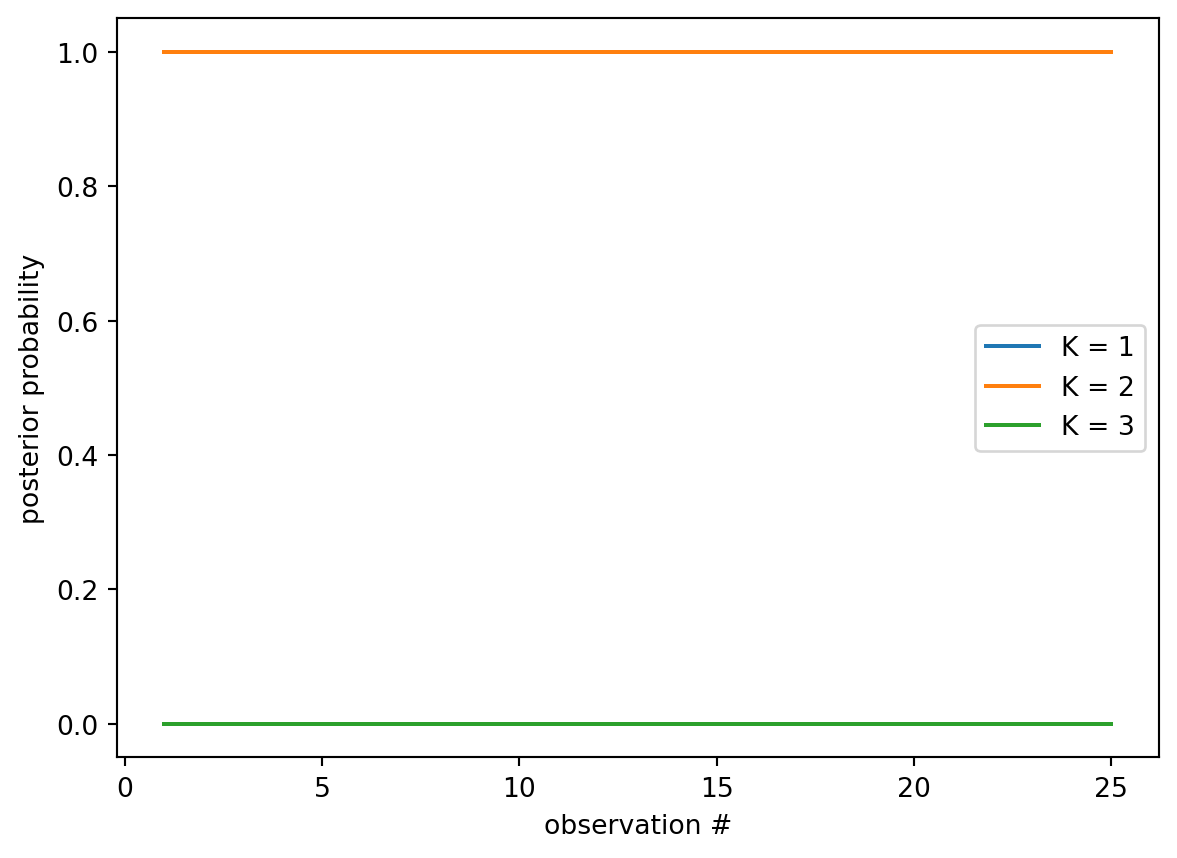
Model comparison live: posterior probability over K=1, 2, 3 as observations accumulate. Truth is K=2.
Occam’s razor, automatic
The suspicious thing is that \(K=3\) doesn’t win — a three-mass model contains every two-mass configuration (set one mass near zero), so its best fit is at least as good. Evidence is not best-fit, though: it averages the likelihood over the model’s whole prior. Extra parameters spread that average across vast regions of configuration space the data rejects, and the dilution is the tax. Complexity isn’t punished by rule; it is punished by arithmetic.
Run it live
(One geometric note: this scenario keeps the second mass at \(x = 3.0\), directly atop a clock — the placement the previous page avoided for parameter estimation; it matters less for the how-many question, as the verdict shows.)
Code
import matplotlib.pyplot as pltimport numpy as npfrom clocks import ( ClockArray, InferenceConfig, MassConfig, NoiseConfig, PriorConfig, SimulationConfig, infer, simulate,)clock_array = ClockArray( positions=np.array([[-6.0], [-3.0], [0.0], [3.0], [6.0]]), track_offset=1.0)truth = MassConfig(positions=np.array([[-2.0], [3.0]]), masses=np.array([0.6, 0.4]))sim = simulate(SimulationConfig( clock_array=clock_array, ground_truth=truth, noise=NoiseConfig(observation_std=0.005), n_observations=25, seed=42,))result = infer(sim.observations, InferenceConfig( clock_array=clock_array, noise=NoiseConfig(observation_std=0.005), prior=PriorConfig(position_range=(-8.0, 8.0), mass_range=(0.1, 2.0)), n_particles=400, n_masses=(1, 2, 3), seed=42,))print(f"Posterior over K: { {k: round(v, 3) for k, v in result.posterior_by_model.items()} }")print(f"Best model: K = {result.best_model}")fig, ax = plt.subplots()steps = np.arange(1, len(result.history) +1)for k insorted(result.posterior_by_model): ax.plot(steps, [h[k] for h in result.history], label=f"K = {k}")ax.set_xlabel("observation #")ax.set_ylabel("posterior probability")ax.set_ylim(-0.05, 1.05)ax.legend()plt.close(fig)fig
Posterior over K: {1: 0.0, 2: 1.0, 3: 0.0}
Best model: K = 2
Posterior probability per candidate K over 25 observations (truth: K=2).
NoteEvidence is a flow, not a snapshot
With only 25 noisy observations and a small particle budget, the verdict here can be less crisp than the 80-observation GIF above — and that is itself the lesson. Evidence accumulates; certainty about how many things exist is bought one observation at a time, exactly like certainty about where they are.