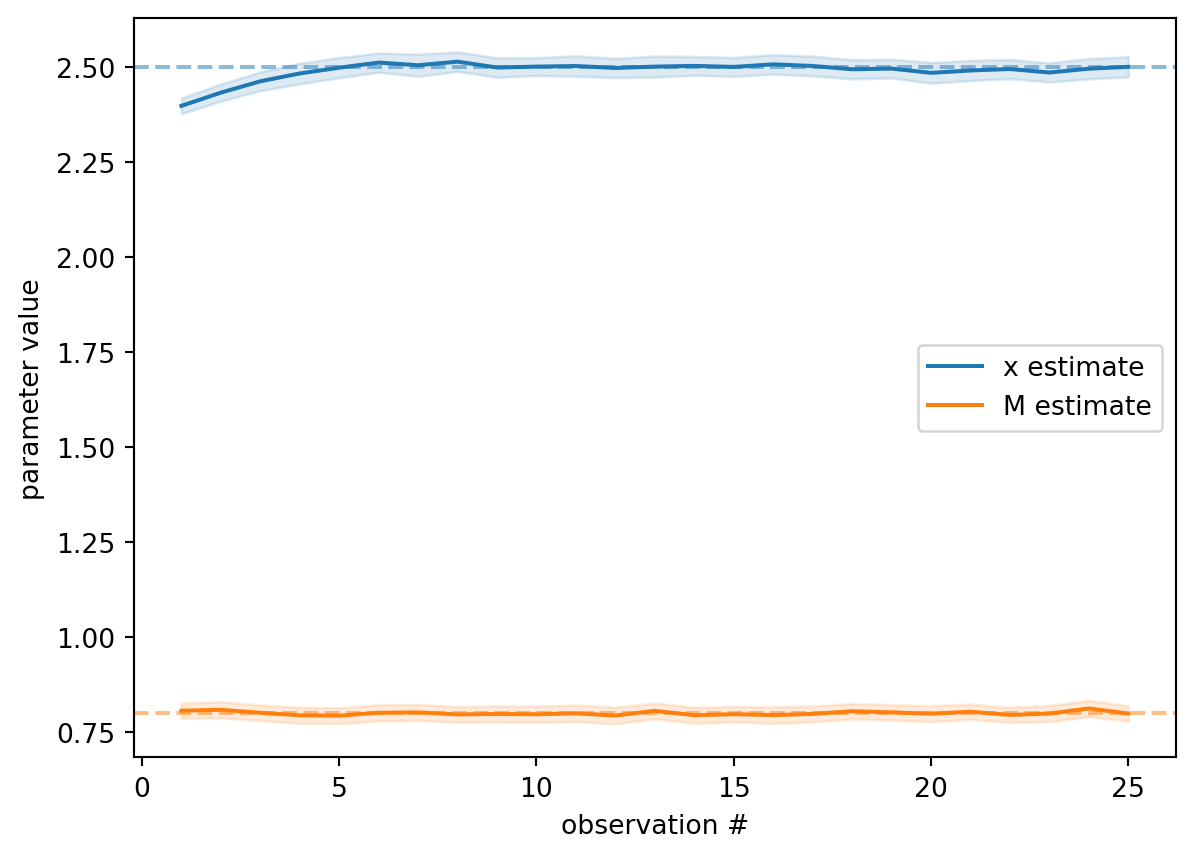
import matplotlib.pyplot as plt
import numpy as np
from clocks import (
ClockArray, InferenceConfig, MassConfig, NoiseConfig,
PriorConfig, SimulationConfig, infer, simulate,
)
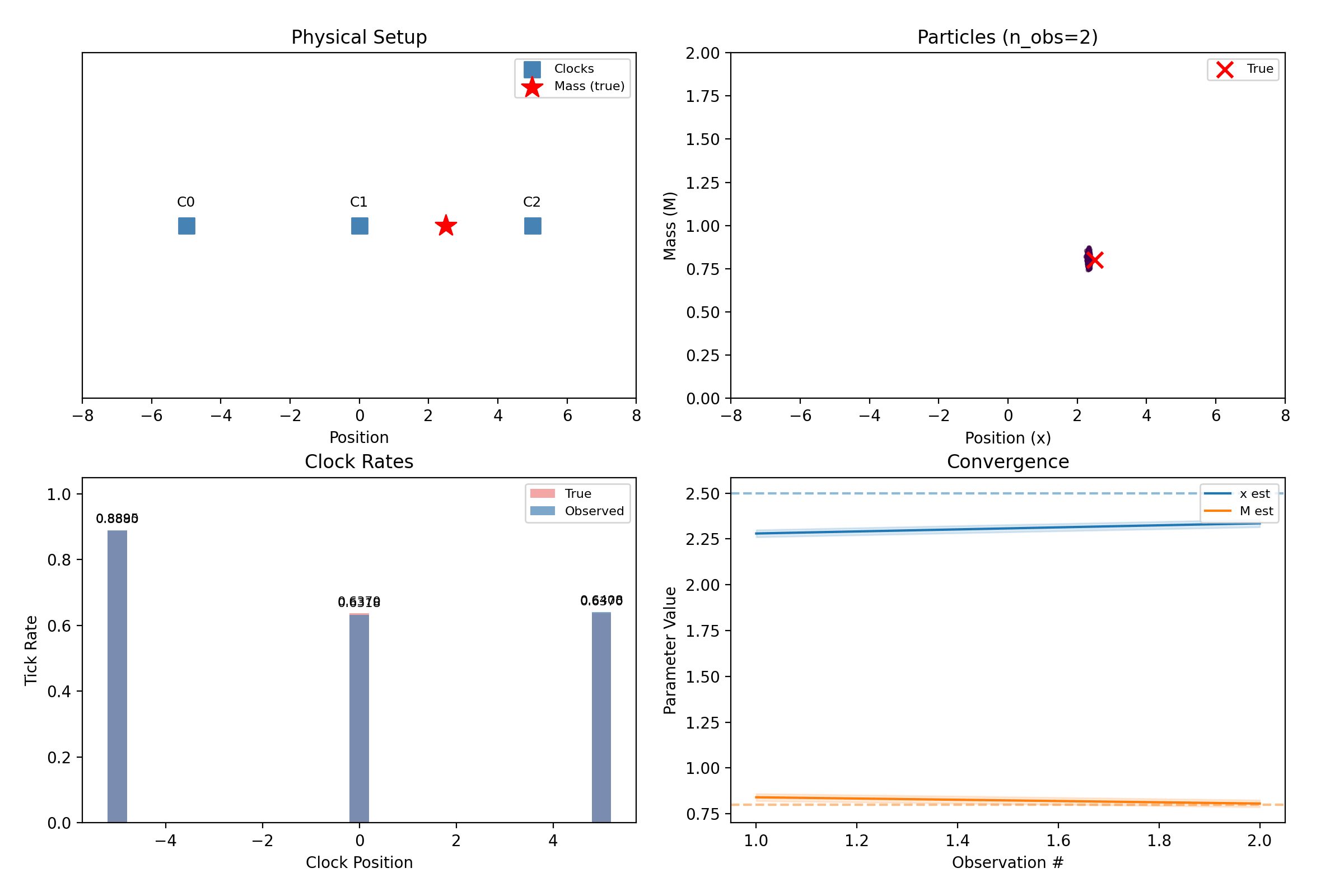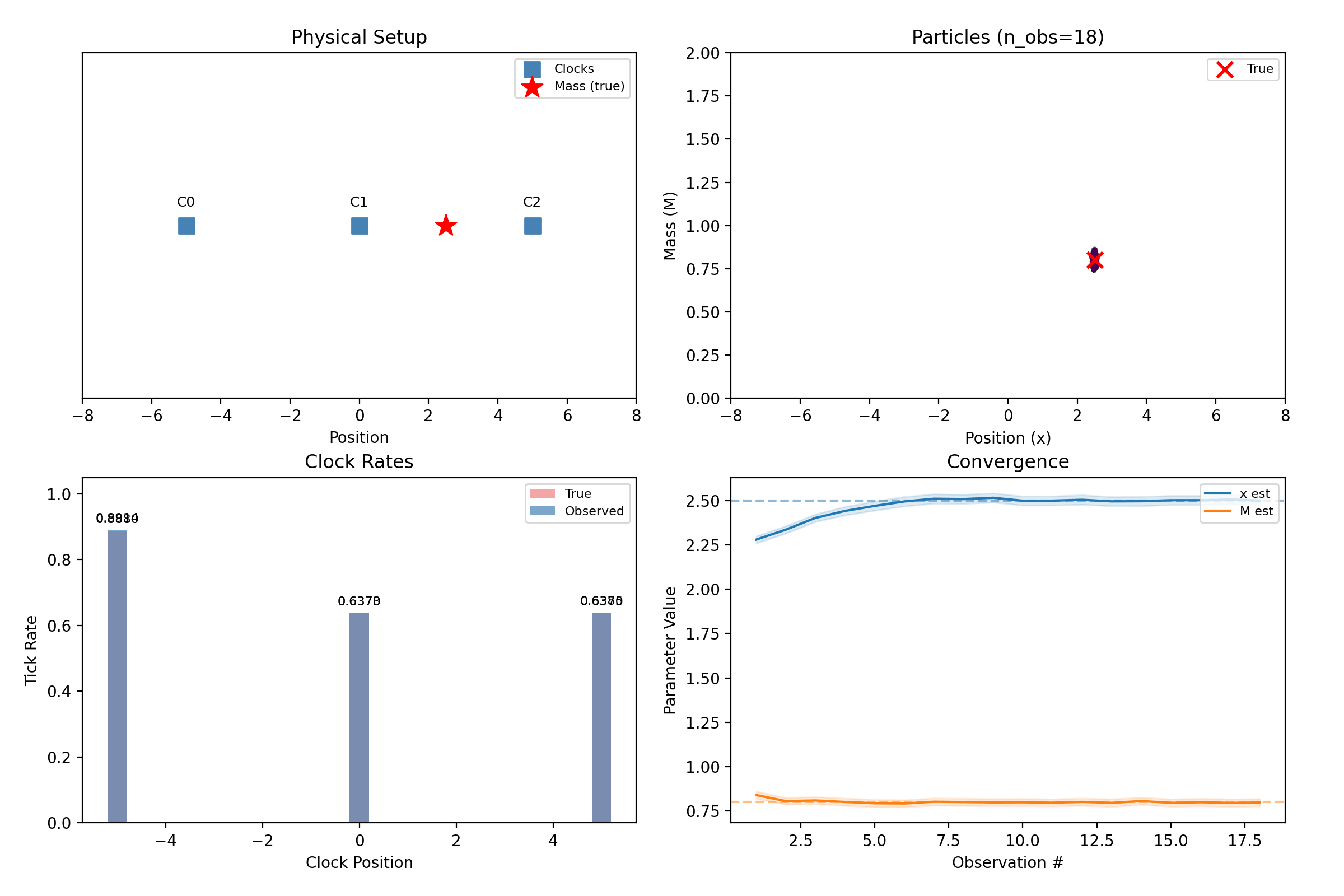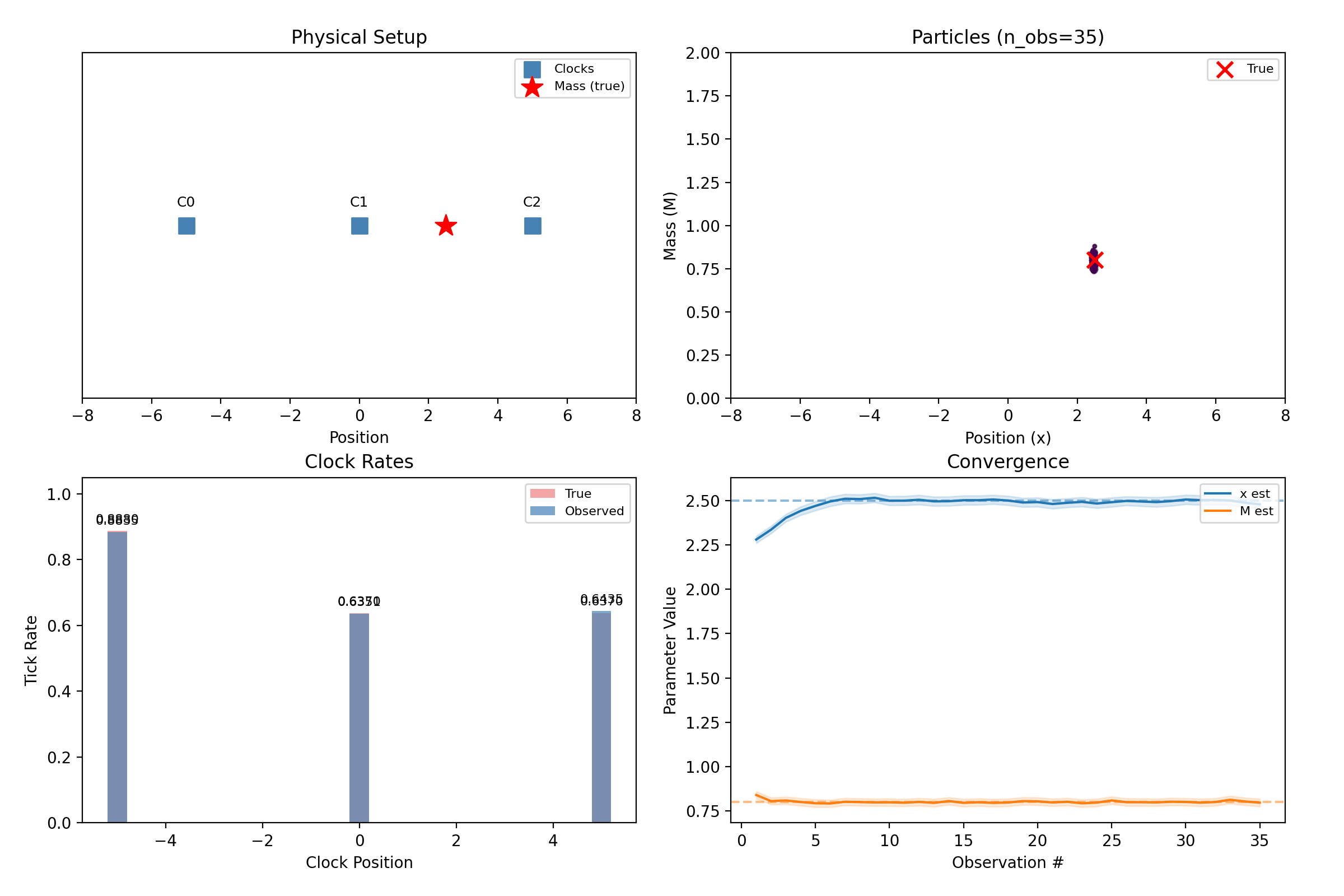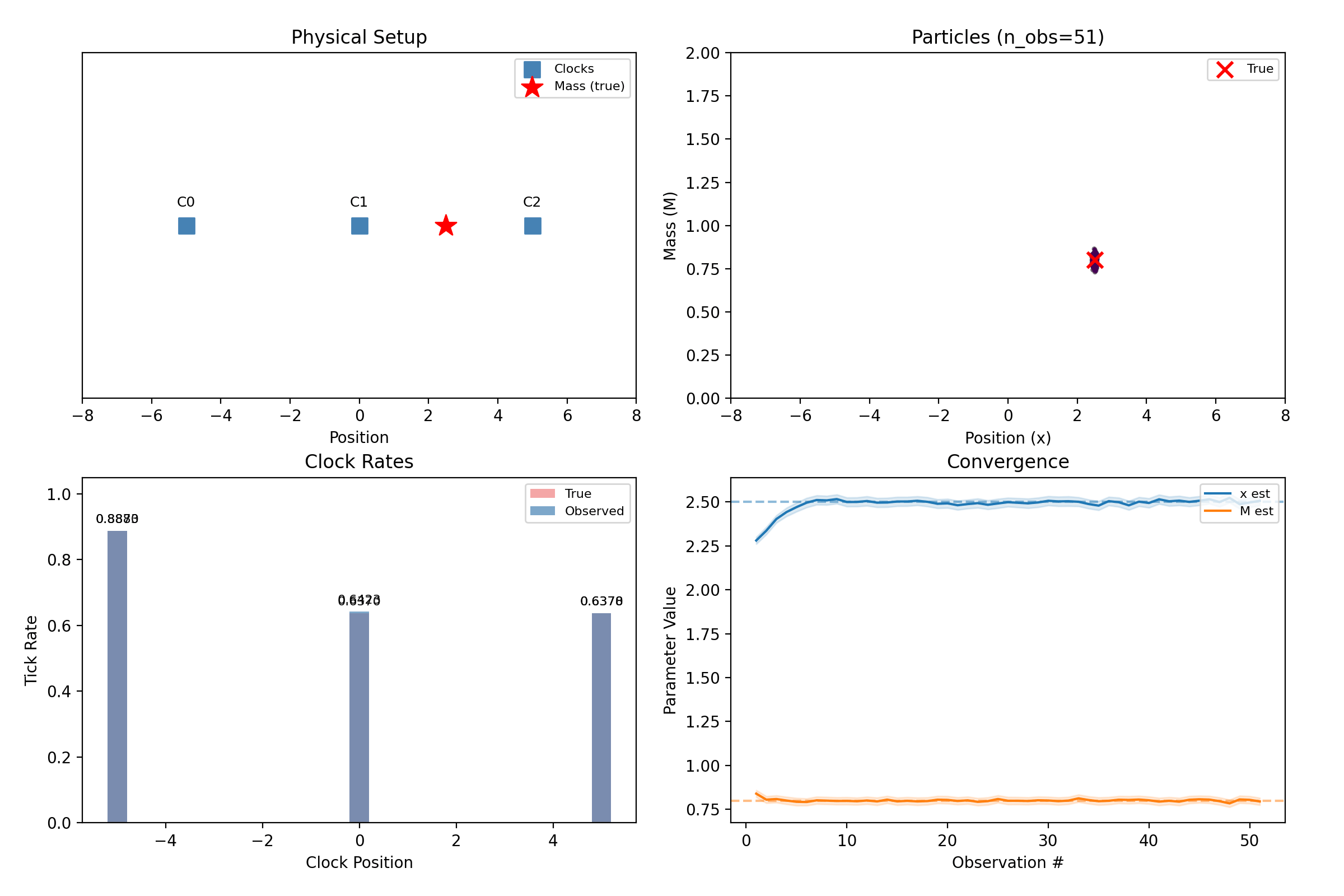
clock_array = ClockArray(positions=np.array([[-5.0], [0.0], [5.0]]), track_offset=1.0)
truth = MassConfig(positions=np.array([[2.5]]), masses=np.array([0.8]))
sim = simulate(SimulationConfig(
clock_array=clock_array, ground_truth=truth,
noise=NoiseConfig(observation_std=0.005), n_observations=25, seed=42,
))
result = infer(sim.observations, InferenceConfig(
clock_array=clock_array, noise=NoiseConfig(observation_std=0.005),
prior=PriorConfig(position_range=(-8.0, 8.0), mass_range=(0.1, 2.0)),
n_particles=400, n_masses=1, seed=42,
))
steps = np.arange(1, len(result.history) + 1)
means = np.array([entry.mean for entry in result.history])
stds = np.array([entry.std for entry in result.history])
fig, ax = plt.subplots()
for j, (label, true_val, color) in enumerate(
[("x", 2.5, "tab:blue"), ("M", 0.8, "tab:orange")]
):
ax.plot(steps, means[:, j], color=color, label=f"{label} estimate")
ax.fill_between(
steps, means[:, j] - stds[:, j], means[:, j] + stds[:, j],
alpha=0.15, color=color,
)
ax.axhline(true_val, color=color, ls="--", alpha=0.5)
ax.set_xlabel("observation #")
ax.set_ylabel("parameter value")
ax.legend()
plt.close(fig)
fig